iText launches iText pdfOCR, a powerful open-source product enabling text recognition in scanned documents and conversion into editable PDFs
iText Group NV, a globally recognized thought-leader and innovator in PDF libraries and solutions, today announced the launch of iText pdfOCR, the newest addition to their award-winning software offering.
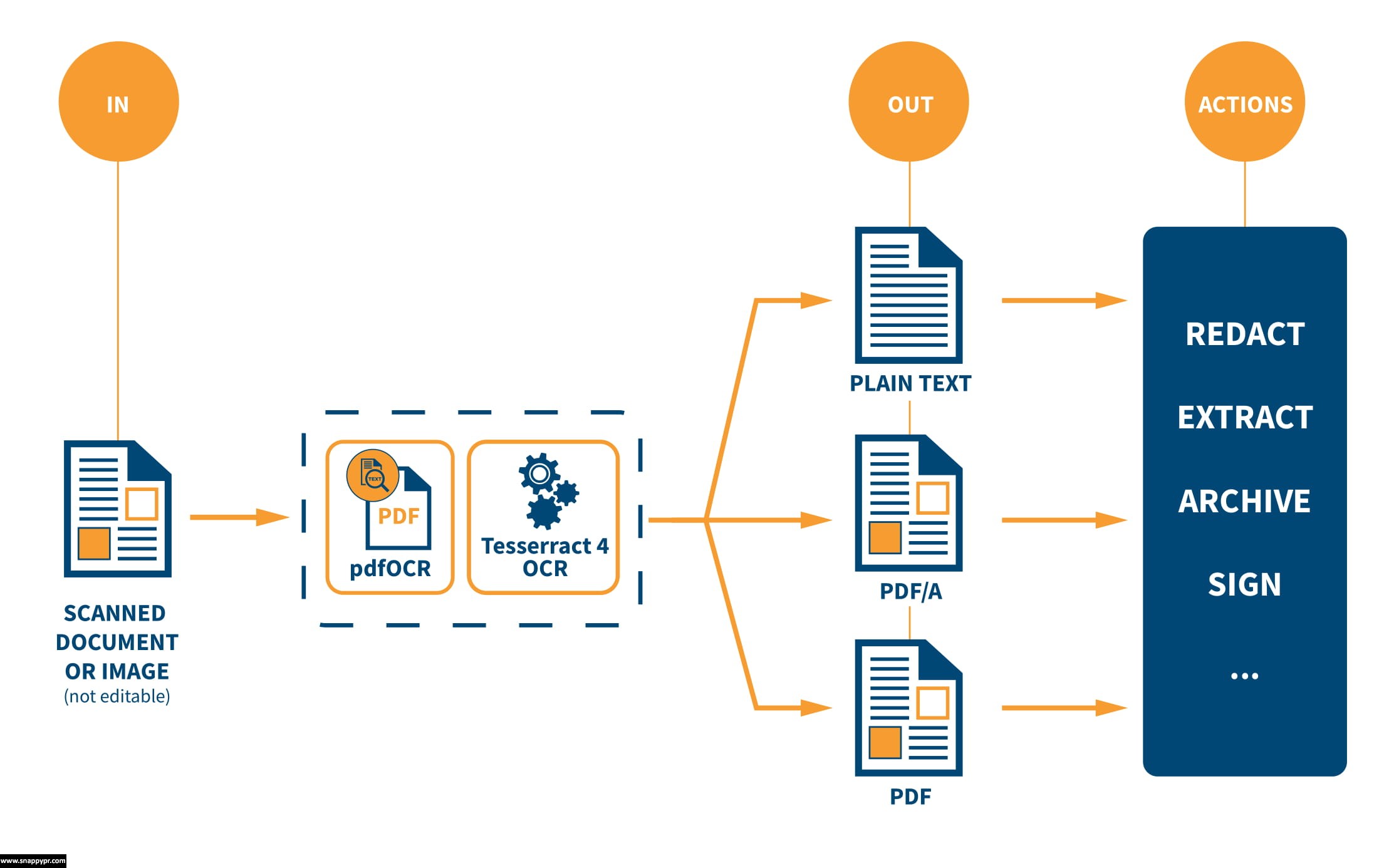
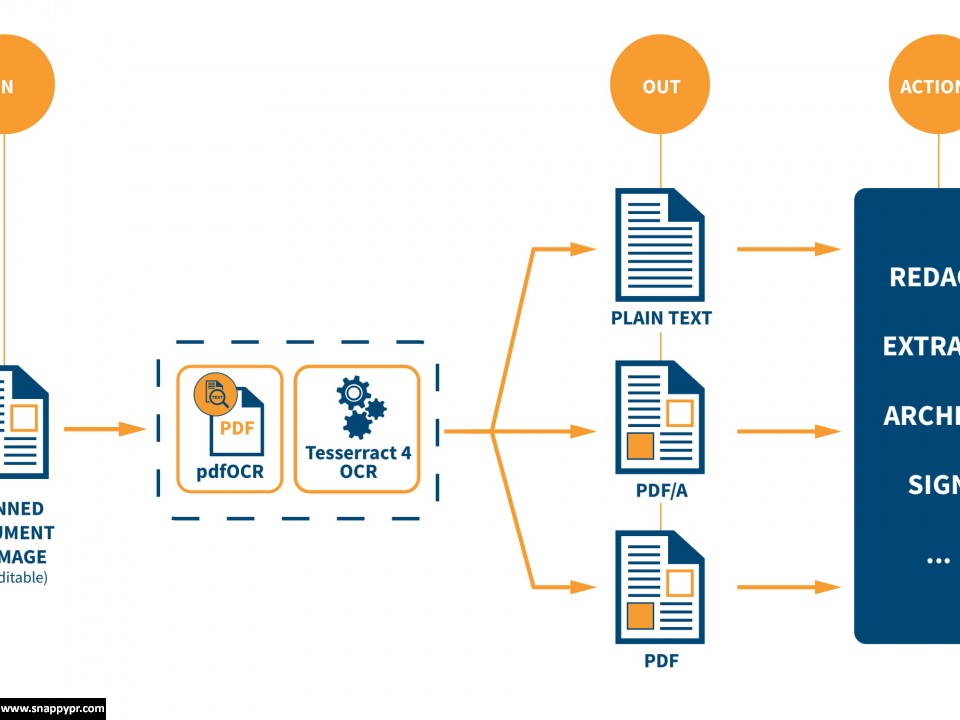
iText pdfOCR, which is part of the renowned iText 7 PDF SDK, offers Optical Character Recognition (OCR) functionality to convert printed text in scanned documents and images into a fully searchable PDF/A-3u compliant format (PDF version 1.7) and make accessing those texts easier and faster. Without machine-readable text, printed or scanned documents cannot be searched, indexed or interpreted. Logical follow-up actions could be data extraction with iText pdf2Data, secure content redaction with iText pdfSweep, or multilingual document recreation with iText pdfCalligraph. With repurposing data with the low-code document generator iText DITO® often being the final cherry on the cake.